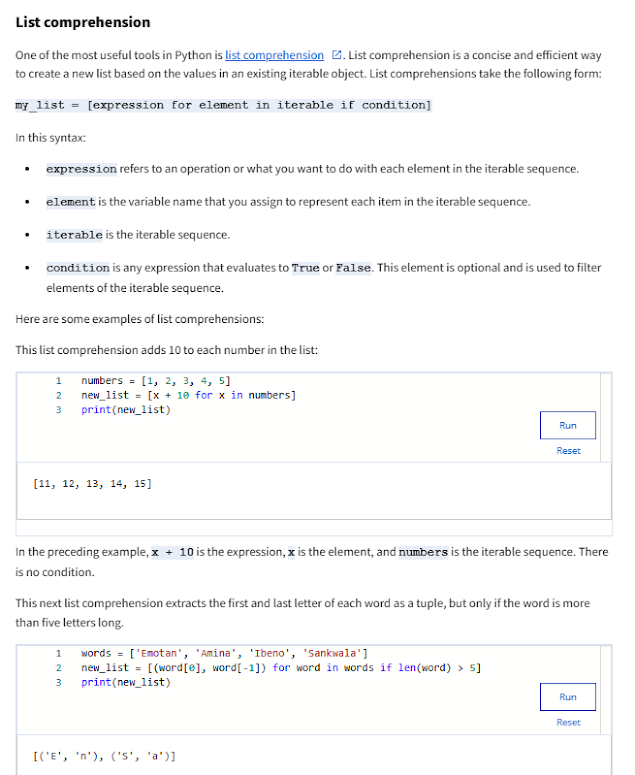
Get started with Python - Google
Get started with Python - a Google Course Subject


Module 1 - Helpful resources and tips





Course descriptions - Overview
The Google Advanced Data Analytics Certificate has seven courses. Get Started with Python is the second course.

Foundations of Data Science — Learn how data professionals operate in the workplace and how different roles in the field of data science contribute to an organization’s vision of the future. Then, explore data science roles, communication skills, and data ethics.
Get Started with Python — (current course) Discover how the programming language Python can power your data analysis. Learn core Python concepts, such as data types, functions, conditional statements, loops, and data structures.
Go Beyond the Numbers: Translate Data into Insights — Learn the fundamentals of data cleaning and visualizations and how to reveal the important stories that live within data.
The Power of Statistics — Explore descriptive and inferential statistics, basic probability and probability distributions, sampling, confidence intervals, and hypothesis testing.
Regression Analysis: Simplify Complex Data Relationships — Learn to model variable relationships, focusing on linear and logistic regression.
The Nuts and Bolts of Machine Learning — Learn unsupervised machine learning techniques and how to apply them to organizational data.
Google Advanced Data Analytics Capstone — Complete a hands-on project designed to demonstrate the skills and competencies you acquire in the program.


Why Jupyter Notebook?
Notebooks are particularly useful for working with data. Here are some ways that Jupyter notebooks excel:
Modular/interactive computing: You can write and execute individual chunks of code in small, manageable chunks, which are called cells. You can run a cell without necessarily having to run the whole notebook. This is especially helpful for data exploration and experimentation. Cells are also helpful with debugging, because they provide a user-friendly way to make a mistake, notice that you made the mistake, and iterate back to correct your mistake, without having to re-execute a whole script.
Integration of code and documentation: Notebooks allow you to combine code, textual explanations, and visualizations like charts, graphs, and tables—all in a single document.
Support for multiple languages: The Advanced Data Analytics program will use Python, but Jupyter notebooks support many other languages, making them powerful and versatile.
Data exploration and analysis: The notebook simplifies working with data by offering tools to load, clean, analyze, and examine it in an elegant interface.
Cloud-based services: Many cloud computing platforms host Jupyter notebooks, which makes it easy to run and share notebooks without setting up a local environment. This is very useful for collaboration.
Libraries and extensions: There is a rich ecosystem of extensions and plugins that enhance functionality for whatever type of project you’re working on.
Resources for more information about Jupyter Notebooks:
Jupyter Notebooks cloud (online)
StackOverflow questions (crowdsource forum to help solve problems)






Module #1 - Object-Oriented Programming








- Attributes allow you to access


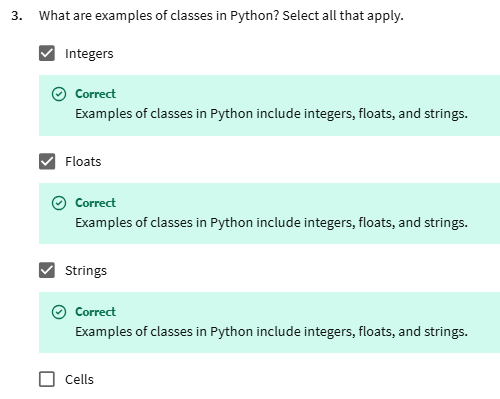
- The four fundamental concepts in object-oriented programming include objects, classes, attributes, and methods.
Week #1 Quiz 1 (Q4 - Q6)



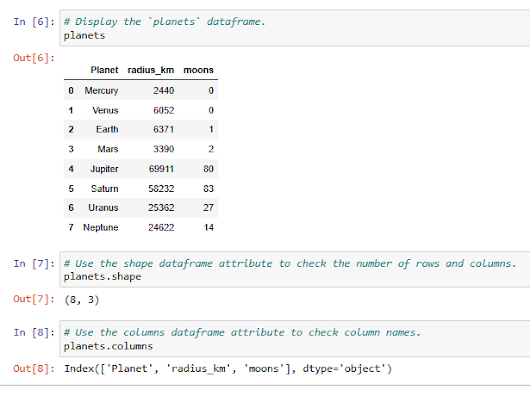
Module 1 - Variables and data types

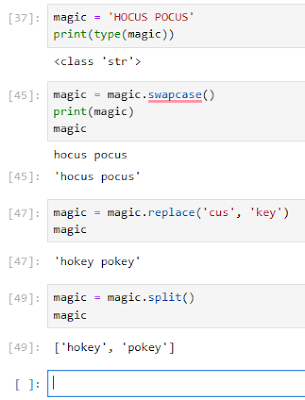
- Variables can store values of any data type. A data type is an attribute that describes a piece of data based on its values, its programming language, or the operations it can perform. In Python, this includes strings, integers, floats, lists, dictionaries, and more.






Module 1 - Create Precise Variable Names
Create Precise Variable Names: https://www.coursera.org/learn/get-started-with-python/lecture/fB03O/create-precise-variable-names
- Naming conventions are consistent guidelines that describe the content, creation date, and version of a file in its name.
- Naming restrictions are rules built into the syntax of the language itself that must be followed.
- Some important naming conventions: To avoid keywords: (that are reserved for a specific purpose and that can only be used for that purpose) e.g. "for," "in," "if," and "else" (which appear in special colors).


e.g.


Module 1 - Data Types and Conversions

- You can use the type function to have the computer tell you the data type. e.g. type(3)
- Run e.g. in JupyterLab or Google Colab: https://colab.research.google.com/
- Run in my Google Colab at: https://colab.research.google.com/drive/1xkygHo655LA_qJlfrEhlz1XSAnPVpojA?usp=sharing

Week 1 - Quiz - Test your knowledge: Using Python syntax



Terms and definitions from Course 2, Module 1
- Argument: Information given to a function in its parentheses
- Assignment: The process of storing a value in a variable
- Attribute: A value associated with an object or class which is referenced by name using dot notation
- Cells: The modular code input and output fields into which Jupyter Notebooks are partitioned
- Class: An object’s data type that bundles data and functionality together
- Computer programming: The process of giving instructions to a computer to perform an action or set of actions
- Data type: An attribute that describes a piece of data based on its values, its programming language, or the operations it can perform
- Dot notation: How to access the methods and attributes that belong to an instance of a class
- Dynamic typing: Variables that can point to objects of any data type
- Explicit conversion: The process of converting a data type of an object to a required data type
- Expression: A combination of numbers, symbols, or other variables that produce a result when evaluated
- Float: A data type that represents numbers that contain decimals
- Immutable data type: A data type in which the values can never be altered or updated
- Implicit conversion: The process Python uses to automatically convert one data type to another without user involvement
- Integer: A data type used to represent whole numbers without fractions
- Jupyter Notebook: An open-source web application for creating and sharing documents containing live code, mathematical formulas, visualizations, and text
- Keyword: A special word in a programming language that is reserved for a specific purpose and that can only be used for that purpose
- Markdown: A markup language that lets the user write formatted text in a coding environment or plain-text editor
- Method: A function that belongs to a class and typically performs an action or operation
- Naming conventions: Consistent guidelines that describe the content, creation date, and version of a file in its name
- Naming restrictions: Rules built into the syntax of a programming language
- Object: An instance of a class; a fundamental building block of Python
- Object-oriented programming: A programming system that is based around objects which can contain both data and code that manipulates that data
- Programming languages: The words and symbols used to write instructions for computers to follow
- String: A sequence of characters and punctuation that contains textual information
- Syntax: The structure of code words, symbols, placement, and punctuation
- Typecasting: Converting data from one type to another (see explicit conversion)
- Variable: A named container which stores values in a reserved location in the computer’s memory
--- ---
Module #2


Module 2 - Define functions and returning values
- To write clean codes
- A function is a body of reusable code for performing specific processes or tasks.
- Built-in functions: print(), str(),
- Github hyperlink: https://github.com/patrickyip0/Get-Start-Python-with-Google/blob/


- Modularity (~ Reusability): Modularity is the ability to write code in separate components that work together and that can be reused for other programs.
- Refactoring: Refactoring is the process of restructuring code while maintaining its original functionality. This is a part of creating self-documenting code.
- Self-documenting code is code written in a way that is readable and makes its purpose clear.
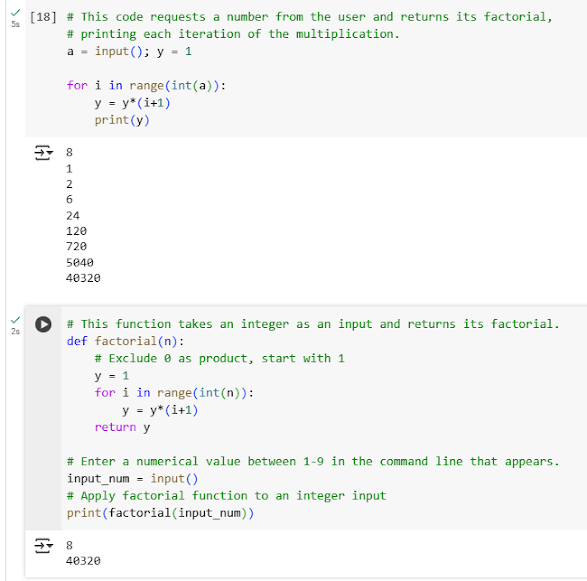

Module 2 - Use comments to scaffold your code
- Github #3 hyperlink: https://github.com/patrickyip0/Get-Start-Python-with-Google/blob/ (#3. Use comments to scaffold your code)




Module 2 - Make comparisons using operators
Link: Make comparisons using operators
- Comparators
- Logical operators: are operators that connect multiple statements together and perform more complex comparisons, e.g. and, or, not ...

Run the lab file in Github (click the icon "Open in Colab")



Module 2 - Use if, elif, else statements to make decisions
Link: Use if, elif, else statements to make decisions





- Wrap Up:

Module 2 - week 2 challenges




Module 3 - week 3
- Learnt: Variables, Data types, Functions, Operators, To write clean code, Conditional statements
- To learn: Loops, Strings

Module 3 - While Loops
Hyperlink: Intro While Loops
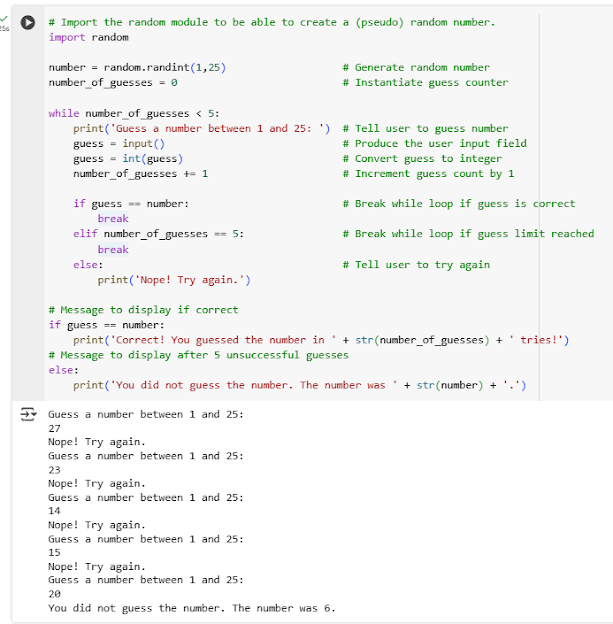
- The word "break" is a keyword that lets you escape a loop without triggering any ELSE statement that follows it in the loop.



Module 3 - For Loops
Hyperlink: Intro For Loops

- For-Loops vs While-Loops
- Use for-loops when there's a sequence of elements that you want to iterate over. E.g., to loop over a variable, such as a record in a dataset, it's always better to use for loops.
- Use while-loops when you want to repeat an action until a boolean condition changes, without having to write the same code repeatedly.


Module 3 - Exemplar Lab
Download or Run in the Github space.


Module 3 - Work With Strings
Hyperlink: Work /w Strings
Try to run Jupyter Notebook in my Github



Module 3 - String Slicing
Hyperlink: String slicing
- Indexing is Python's way of letting us refer to individual items within an iterable by their relative position, allowing us to select, filter, edit and manipulate data.
- Indexing can be used on: strings, lists, tuples and most other iterable data types.
- Indexing lets us slice strings to create smaller strings, or substrings.



Python running in Jupyter Notebook (Github.dev codespace)



Module 3 - Format Strings
Hyperlink: Format Strings
- The format method formats and inserts specific substrings into designated places within a larger string. format()

Quiz:








Module 3 Challenge



Module 4 - Lists & Tuples - Welcome


- Data Structures are collections of data values or objects that contain different data types.

- Two of the most important libraries and packages for data professionals:
- 1) Numerical Python (NumPy), which is known for its high-performance computational power.
- Data professionals use NumPy to rapidly process large quantities of data. It's so useful for analyzing large and complex datasets.
- 2) Python Data Analysis Library (Pandas), which is a key tool for advanced data analytics.
- Pandas makes analyzing data in the form of a table with rows and columns easier and more efficient, because it has tools specifically designed for the job.
- List is a data structure that helps store, and manipulate an ordered collection of items, e.g. a list of email addresses associated with a user account.
- It allows indexing and slicing.
- A sequence is a positionally ordered collection of items. Lists are sequences of elements of any data type.
- Note that different data structures are either mutable or immutable -- Mutability refers to the ability to change the internal state of a data structure.
- Lists are mutable (their elements can be modified, added, or removed) while strings are immutable.



Module 4 - Modify the contents of a List
Hyperlink: Module 4 - Modify the Contents of Lists
- append(element) : append method adds an element to the end of a list.
- XXX.insert(#, yyy) : insert(index#, element) is a function that takes an index as the first parameter and an element as the second parameter, then inserts the element into a list.
- XXX.remove(index#, element) is a method that removes an element from a list.
- xxx.pop(index#) : pop(#) function extracts an element from a list by removing it at a given index number.
- Forgot to upload the dataset file "train.csv" to Github => Errors
- In terminal, run command: git pull origin main # or 'master' if using older repo
- Python REPL for interactive debugging





Module 4 - Intro Tuples
Hyperlink: Module 4 - Intro Tuples
- Module 4: More with Loops, Lists and Tuples













Module 4 - zip(), enumerate(), and list comprehension
Hyperlink: Module 4 - zip(), enumerate() and list()
enumerate( )- Quiz:







Module 4 - Introduction to Dictionaries
Hyperlink: Module 4 - Intro Dictionaries
- Dictionary is a data structure that consists of a collection of key-value pairs.


- Dict( ) can be used to create a dictionary function.
- Immutable keys include: integers, floats, tuples and strings.
- Mutable data types cannot be used as keys: Lists, Sets, and other dictionaries.






- A set is a data structure in Python that contains only unordered, non-interchangeable elements.
- Sets are instantiated with the set( ) function or non-empty braces.
- set( ) is a function takes an iterable as an argument and returns a new set object.
- Each element in sets must be unique.
- Reference for "iterable": iterable, iterator and generator in Python
- To define an empty set, you have to use the set( ) function.
- Because the elements inside a set are immutable, a set cannot be indexed or sliced.
- intersection( ) finds the elements that two sets have in common.
- Union( ) finds all the elements from both sets.
- Difference( ) finds the elements present in one set, but not the other.
- Symmetric_difference( ) finds elements from both sets that are mutually not present in the other.
- Ref.: Reference guide: Sets
Quiz:









Module 4 - The Power of Packages (Numpy)
Hyperlink: Module 4 - The Power of Packages (Numpy)
- A library, or package refers to a reusable collection of code. It also contains related modules and documentation.
- Python libraries: matplotlib, seaborn, Numpy and Pandas.
- Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
- Seaborn is a data visualization library that's based on matplotlib. It provides a simpler interface for working with common plots and graphs.
- NumPy (Numerical Python) is an essential library that contains multidimensional array and matrix data structures and functions to manipulate them. This library is used for scientific computation.
- Pandas (Python Data Analysis) is a powerful library built on top of NumPy that's used to manipulate and analyze tabular data.
- Scikit-learn, a library, and statsmodels, a package, consist of functions. Data professionals can use them to test the performance of statistical models.
- Modules are accessed from within a package or a library. They are Python files that contain collections of functions and global variables.
- Commonly used modules for data professional work are: Math and random (functions).


Module 4 - Introduction to Numpy
Hyperlink: Module 4 - Introduction to Numpy
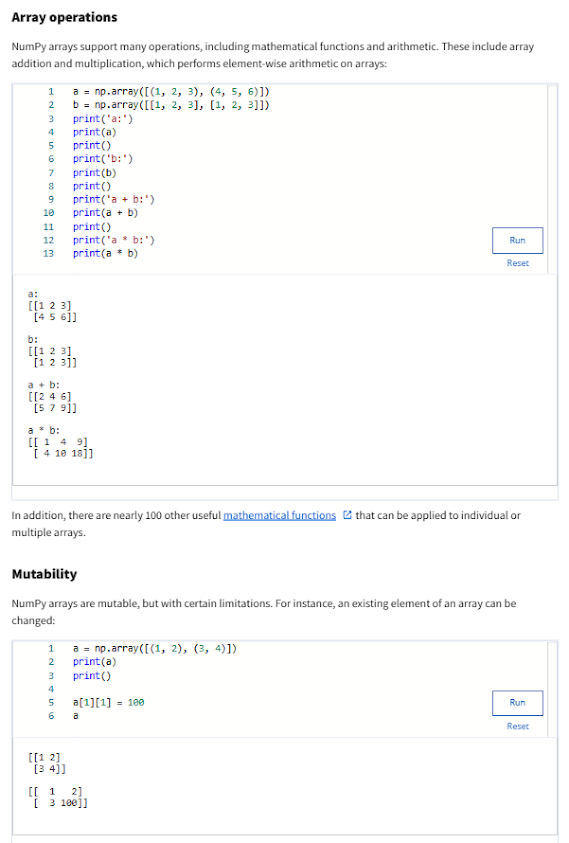
- NumPy's power comes from vectorization. Vectorization enables operations to be performed on multiple components of a data object at the same time (especially useful when manipulating very large quantities of data):
- More efficient and faster
- Vectors also take less memory space.
- Import statement is used to load an external library, package, module, or function into your computing environment.
- Aliasing lets you assign an alternate name, or alias, by which you can refer to something (abbreviating Numpy to np).
- ".shape" attribute to confirm the shape of an array.
- ".ndim" attribute to confirm the number of dimensions the array has.




















Module 5 - Introduction to Pandas
Hyperlink: Module 4 - Introduction to Pandas
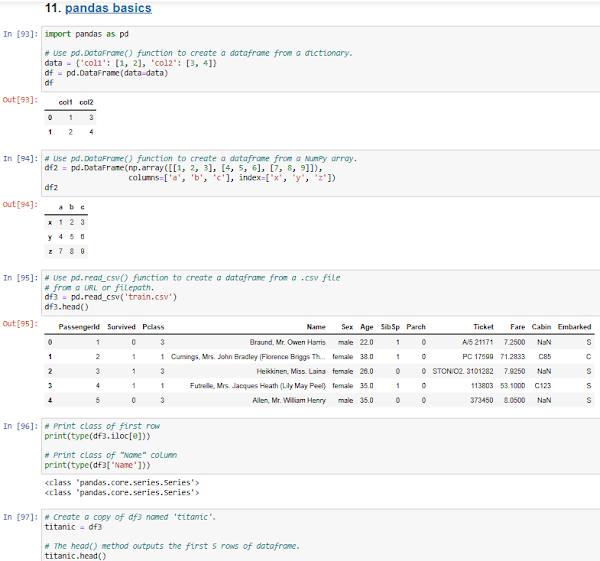
- Pandas' key functionality is the manipulation and analysis of tabular data - i.e. data in the form of a table (with rows and columns), e.g. a spreadsheet.
- Pandas has two core object classes: dataframes and series
- Dataframe is a two-dimensional, labeled data structure with rows and columns: e.g. a spreadsheet or a SQL table.
- Below 1st example is a dataframe created from a dictionary, where each key of the dictionary represents a column name, and the values for that key are in a list.
- The 2nd example is created from a NumPy array, resembling a list of lists, where each sub-list represents a row of the table. [execution #94]
- Series is a One-D labeled array.
- NaN = Not a Number = Null values that are represented in pandas, standing for "not a number".
- Use dot notation, but this only works if the column name does not contain any whitespaces.: e.g. df3.Age or df3.['Age']
- Better to use bracket notation, because it makes the code easier to read: e.g. df3[['Name', 'Age']]
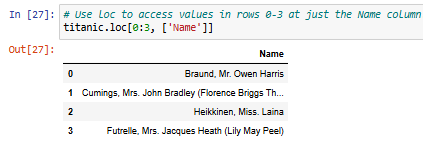
- To select rows or columns by index, you'll need to use iloc[ ]: e.g. df3.iloc[0] # row 0
- e.g. row 0 of data frame: df3.iloc[[0]] # the whole row 0 (also shown in [105])
- e.g. entire rows below: df3.iloc[0:3] # the whole row 0 to 2 (also in [106])
- e.g. select subsets: df3.iloc[0:3, [3, 4]] # the rows 0 to 2 at columns 3, 4 (in [108])
- e.g. get a dataframe view of all rows at column #3: df3.iloc[:, [3]] # all rows at column #3 (in [107])
- e.g. use iloc to access value in row 0, column 3: df3.iloc[0, 3]
- Boolean masking is a filtering technique that overlays a Boolean grid onto a dataframe in order to select only the values in the dataframe that align with the True values of the grid.
- Grouping and Aggregation m4 分組 & 聚合
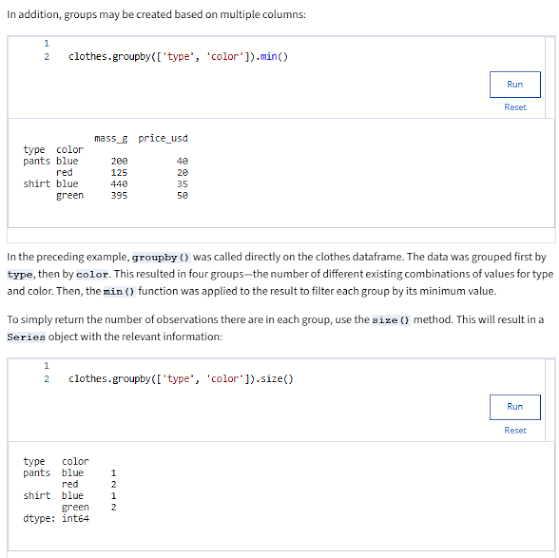
- Groupby is a pandas DataFrame method that groups rows of the dataframe together based on their values at one or more columns, which allows further analysis of the groups: df4.groupby(['type']).sum( ) # sum, mean, min, max, median, count( )
- dataframe df:
- agg( ) = aggregate = a Panda groupby method allows you to apply multiple calculations to groups of data.
- Link: More on grouping and aggregation : .groupby( ), .min (), .size( )
- Panda Functions: concat( ) and merge( )
- The function "concat( )" combines data either by adding it horizontally as new columns for existing rows, or vertically as new rows for existing columns.
































----- =====
Top Popular IDEs (Integrated Development Platforms) for Python Development

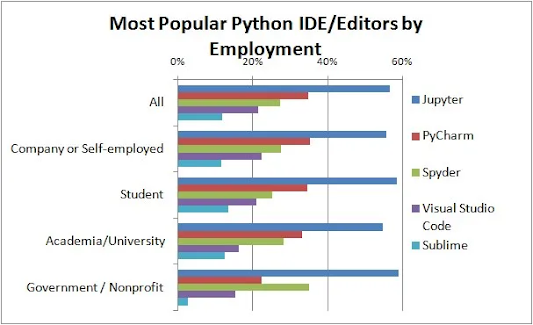
(Source: Peng Liu https://rocmind.com/2019/03/23/here-are-the-most-popular-python-ides-editors/)
Top 5 Best IDEs to Use 2024: https://keploy.io/blog/community/top-5-best-ides-to-use-for-python-in-2024
- PyCharm
- VS Code
- Spyder
- Jupyter Notebook
- Thonny

- Tutorials: w3schools
- Tools: replit (AI dev tools for softw projects)

- Learn by doing projects: pygame (to master py knowledge)
- Featured Chatbot, web-scraping AI app, Video analytic AI, Recognizing AI (using openAI, TensorFlow, Hugging Face)


- Software Frameworks: Dash, Streamlit, Flask
- Reference: Replit's public open-source projects => Deploy

















After the admin of the project has inspected your pull request, it can be allowed to squash & merge:




- ^ Tutorial: Python Interactive - Python Standard REPL
- Type python3 in the Terminal
- Interactive help command REPL: >>> help() interactive help, help(object)
- Ref Notes: Converting Jupyter Notebook to Python Scripts (in 3 ways)
- Command: !jupyter nbconvert --to python Lab_1.ipynb <example>


- YouTube: Most Popular Programming Languages: Data from 1958 to 2025
- YouTube AI老司机 : 用AI深扒巴菲特 20 年持仓,Gemini挖出了3个教科书上没有的秘密!

- Steps 1a:> Input ChatGPT: 汇总SEC过去20年(2004-2024)伯克希尔的13F数据,使用Python脚本自动爬取、解析并导出成表格。请给出python的脚本代码



- YouTube 技术爬爬虾 TechShrimp: Powerful VS Code (IDE) uses: 宇宙级编辑器VSCode,你真的会用么? 提高生产力的大量技巧
- Extensions (Plugins) GitLens:
- Commit Graph:
- Extensions (Plugins) SSH: Remote-Explorer: Remote-Development with Backend Servers: (6:30 / 15:22):
- (7:05 / 15:22) -> Connect in New Window -> "Linux" -> Continue -> Enter password:
- Extension WSL: Windows Subsystem for Linux (8:25 / 15:22) To run Linux in Windows Environment > VS Code:
- Command > Powershell > Ubuntu (below pic) > code . <CR> :
- Extensions MarketPlace: Postman VS Code <or> Thunder Client <or> Rest Client:
(click to enlarge)
(click to enlarge)
Explaining the use of "REST Client" to do http Get, Put: "Copy Request As cURL":
The Extension "Rest Client" can then recognize your command of "Request As cURL" (Paste below):
- Hightlight, right-click to choose "Command Palette" (Ctr+Shift+P) => ">" "Rest Client: Send Request" (Ctr+Alt+R) : (as shown below)
- MySQL: 10:52/15:22, & SQLite (can view the Biggest Wechat Database) 11:00, Redis:
- Front-end (VS Code leads the front-end dev) 11:15/15:22, "Vue 3 Snippets" (few word auto-gen to codes), "Vue Official" (代码补全、检查代码格式):
- React: "ES7 + React/Redux/React-Native snippets" (11:42/15:22) auto-gen-codes:
- "Auto Rename Tag" (11:55/15:22):
- "JavaScript Debugger" (12:05), "Live Server" (12:16) (when html file is open, click "go live" button):
- --> auto post & open a html web page:
- "CSS Peek" > Pressing "Ctr" with the mouse pointer will display the definition of the CSS: (12:44)
- Prettier - Code formatter (12:53):
Format Document / (Shortcut)(Shift Alt + F):
- (Similar Function) ESLint (13:20):
- Console Ninja (13:25):Console log output (控制台輸出) (shown directly on the right of your source code)
- Coding Assistant: Polacode (13:40 / 15:22): Generate a screenshot of your source code
- Code Spell Checker (14:08):
- Markdown Preview Enhanced (14:25):
- TODO Highlight (14:50):
- Search "AI": Github Copilot (15:10): Tabnine AI chat (15:13): IntelliPHP (15:15):






































留言
張貼留言